Web scraping je proces zhromažďovania a analyzovania nespracovaných údajov z webu. Komunita Pythonu vytvorila niekoľko celkom výkonných nástrojov na web scraping.
Internet je pravdepodobne najväčším zdrojom informácií - a dezinformácií - na našej planéte. Mnohé odbory, ako napríklad dátová veda, obchodné spravodajstvo a investigatívne reportáže, môžu mať zo zhromažďovania a analýzy údajov z webových stránok obrovský úžitok.
a) Parsovanie údajov webovej lokality pomocou Stringových metód a regulárnych výrazov
b) Rozbor údajov webovej lokality pomocou analyzátora HTML
c) Interakcia s formulármi a inými webovými komponentmi
Niektoré webové stránky výslovne zakazujú používateľom získavať ich údaje pomocou automatizovaných nástrojov, ako sú tie, ktoré vytvoríte v tejto prvej úlohe. Webové lokality to robia z dvoch možných dôvodov:
a) Webová lokalita má dobrý dôvod chrániť svoje údaje. Napríklad služba Google Maps vám nedovolí vyžiadať si príliš veľa výsledkov príliš rýchlo.
b) Opakované zadávanie mnohých požiadaviek na server webovej lokality môže spotrebovať šírku pásma, spomaliť webovú lokalitu pre ostatných používateľov a potenciálne preťažiť server tak, že webová lokalita prestane úplne reagovať.
Pred použitím svojich zručností v jazyku Python na web scraping by ste mali vždy skontrolovať zásady prijateľného používania cieľovej webovej lokality a zistiť, či prístup k webovej lokalite pomocou automatizovaných nástrojov nie je porušením podmienok používania. Z právneho hľadiska je web scraping proti želaniu webovej lokality veľmi šedá zóna.
Upozorňujeme, že nasledujúce techniky môžu byť nezákonné, ak sa používajú na webových stránkach, ktoré zakazujú web scraping.
Jedným z užitočných balíkov na web scraping, ktorý nájdete v štandardnej knižnici jazyka Python, je urllib, ktorý obsahuje nástroje na prácu s adresami URL. Konkrétne modul urllib.request obsahuje funkciu urlopen(), ktorú možno použiť na otvorenie adresy URL v rámci programu.
V interaktívnom okne IDLE zadajte nasledujúci príkaz na import funkcie urlopen():

Webová stránka, ktorú otvoríme, sa nachádza na nasledujúcej adrese URL:

Ak chcete otvoriť webovú stránku, odovzdajte url funkcii urlopen():

urlopen() vráti objekt HTTPResponse:

Ak chcete získať HTML zo stránky, použite najprv metódu .read() objektu HTTPResponse, ktorá vráti postupnosť bajtov. Potom použite metódu .decode() na dekódovanie bajtov na reťazec pomocou UTF-8:

Teraz môžete printovať HTML a zobraziť obsah webovej stránky:
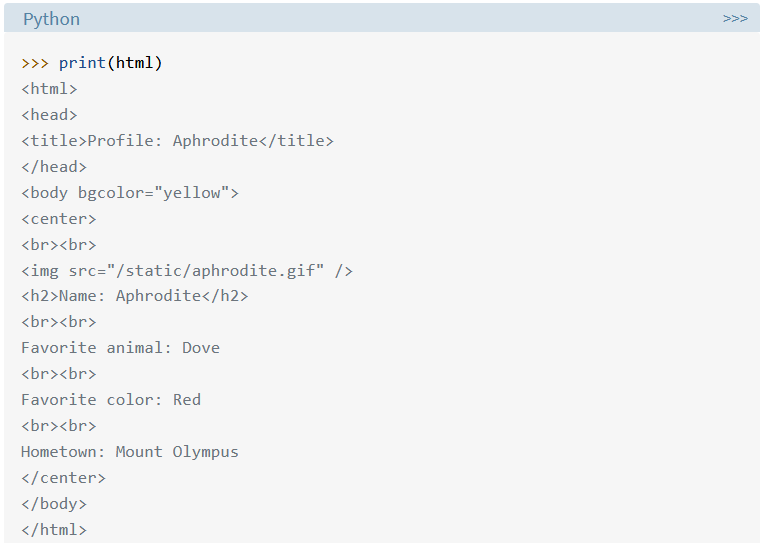
Keď máme HTML ako text, môžete z neho získať informácie niekoľkými rôznymi spôsobmi.
Jedným zo spôsobov, ako získať informácie z HTML webovej stránky, je použitie reťazcových metód. Napríklad pomocou funkcie .find() môžete v texte HTML vyhľadať značky a získať názov webovej stránky.
Získajme názov webovej stránky, ktorý ste si vyžiadali v predchádzajúcom príklade. Ak poznáte index prvého znaku názvu a prvého znaku uzatváracej značky , môžete na extrakciu názvu použiť reťazec slice.
Keďže funkcia .find() vracia index prvého výskytu podreťazca, môžete získať index úvodného tagu odovzdaním reťazca "<title>" funkcii .find():

Nechcete však mať index značky . Chcete index samotného názvu. Ak chcete získať index prvého písmena v nadpise, môžete k indexu title_index pridať dĺžku reťazca "<title>":

Teraz získate index uzatváracej značky </title> odovzdaním reťazca "</title>" funkcii .find():

Nakoniec môžete extrahovať nadpis rozrezaním reťazca html:

HTML v reálnom svete môže byť oveľa komplikovanejšie a oveľa menej predvídateľné ako HTML na stránke profilu Aphrodite. Tu je ďalšia profilová stránka s trochu chaotickejším HTML, ktorú môžete scrapnúť: url = "http://olympus.realpython.org/profiles/poseidon"
Skúste extrahovať názov z tejto novej adresy URL rovnakou metódou ako v predchádzajúcom príklade:
>>> url = "http://olympus.realpython.org/profiles/poseidon"
>>> page = urlopen(url)
>>> html = page.read().decode("utf-8")
>>> start_index = html.find("") + len("<title>")</p>
>>> end_index = html.find("")
>>> title = html[start_index:end_index]
>>> title
'\n\nProfil: Poseidon'</p>
Ups! Do nadpisu sa zamiešalo trochu HTML. Prečo?
HTML pre stránku /profiles/poseidon vyzerá podobne ako stránka /profiles/aphrodite, ale je tu malý rozdiel. Úvodný tag má pred uzatváracou uhlovou zátvorkou (>) navyše medzeru, čím sa vykresľuje ako <title >.</p>
Funkcia html.find("") vráti hodnotu -1, pretože presný podreťazec "<title>" neexistuje. Keď sa -1 pripočíta k premennej len("<title>"), ktorá je 7, premennej start_index sa priradí hodnota 6.</p>
Znak na indexe 6 reťazca html je znak nového riadku (\n) tesne pred úvodnou uhlovou zátvorkou (<) značky . To znamená, že html[start_index:end_index] vráti celé HTML začínajúce týmto novým riadkom a končiace tesne pred značkou .
Takéto problémy sa môžu vyskytnúť nespočetným množstvom nepredvídateľných spôsobov. Potrebujete spoľahlivejší spôsob extrakcie textu z jazyka HTML.
Základné informácie o regulárnych výrazoch
Regulárne výrazy - alebo skrátene regexy - sú vzory, ktoré možno použiť na vyhľadávanie textu v reťazci. Python podporuje regulárne výrazy prostredníctvom modulu re štandardnej knižnice.
Poznámka: Regulárne výrazy nie sú špecifické pre Python. Sú všeobecným konceptom programovania a možno ich použiť v akomkoľvek programovacom jazyku.
Ak chcete pracovať s regulárnymi výrazmi, najprv musíte importovať modul re:
>>> import re
Regulárne výrazy používajú na označenie rôznych vzorov špeciálne znaky nazývané metaznaky. Napríklad znak hviezdičky (*) označuje nula alebo viac znakov, ktoré sa nachádzajú tesne pred hviezdičkou.
V nasledujúcom príklade použijete funkciu findall() na vyhľadanie akéhokoľvek textu v reťazci, ktorý zodpovedá danému regulárnemu výrazu:

Prvým argumentom funkcie re.findall() je regulárny výraz, ktorý chcete porovnať, a druhým argumentom je reťazec, ktorý sa má testovať. Vo vyššie uvedenom príklade hľadáte vzor "ab*c" v reťazci "ac".
Regulárny výraz "ab*c" sa zhoduje s akoukoľvek časťou reťazca, ktorá začína písmenom "a", končí písmenom "c" a medzi nimi je nula alebo viac výskytov písmena "b". re.findall() vráti zoznam všetkých zhody. Reťazec "ac" zodpovedá tomuto vzoru, preto je vrátený v zozname.
Tu je ten istý vzor aplikovaný na rôzne reťazce:

Všimnite si, že ak sa nenájde žiadna zhoda, funkcia findall() vráti prázdny zoznam.
Pri porovnávaní vzorov sa rozlišujú veľké a malé písmená. Ak chcete tento vzor porovnať bez ohľadu na veľkosť písmen, potom môžete odovzdať tretí argument s hodnotou re.IGNORECASE:

V module re je ešte jedna funkcia, ktorá je užitočná na analyzovanie textu. re.sub(), čo je skratka pre substitute, umožňuje nahradiť text v reťazci, ktorý zodpovedá regulárnemu výrazu, novým textom. Chová sa podobne ako metóda .replace() pre reťazce.
Argumenty odovzdané funkcii re.sub() sú regulárny výraz, za ktorým nasleduje text na nahradenie a potom reťazec. Tu je príklad:

Možno to nebolo celkom to, čo ste očakávali.
Funkcia re.sub() používa regulárny výraz "<.*>" na nájdenie a nahradenie všetkého medzi prvým < a posledným >, čo siaha od začiatku po koniec. Je to preto, že regulárne výrazy jazyka Python sú chamtivé, čo znamená, že sa snažia nájsť čo najdlhšiu zhodu, keď sa používajú znaky ako *.
Ako alternatívu môžete použiť neochotný vzor *?, ktorý funguje rovnako ako * s tým rozdielom, že zodpovedá najkratšiemu možnému reťazcu textu:

Tentoraz funkcia re.sub() nájde dve zhody, a , a nahradí reťazec "ELEPHANTS" za obe zhody.
Hoci regulárne výrazy sú vo všeobecnosti skvelé na porovnávanie vzorov, niekedy je jednoduchšie použiť parser HTML, ktorý je výslovne určený na analyzovanie stránok HTML. Existuje mnoho nástrojov jazyka Python napísaných na tento účel, ale knižnica Beautiful Soup je dobrá na začiatok.
Inštalácia Beautiful Soup
Ak chcete nainštalovať Beautiful Soup, môžete v termináli spustiť nasledujúci príkaz:
$ python3 -m pip install beautifulsoup4
Vytvorenie objektu BeautifulSoup
Do nového okna editora zadajte nasledujúci program:
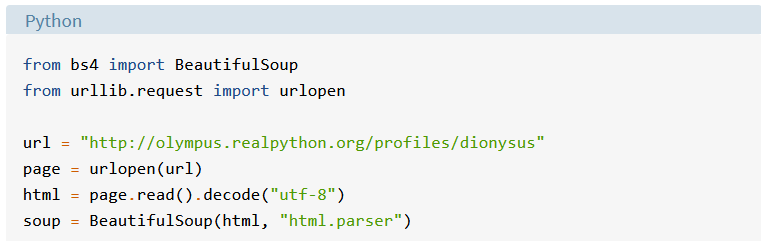
Tento program robí tri veci:
1. Otvorí adresu URL http://olympus.realpython.org/profiles/dionysus pomocou funkcie urlopen() z modulu urllib.request
2. Prečíta HTML zo stránky ako reťazec a priradí ho do premennej html
3. Vytvorí objekt BeautifulSoup a priradí ho do premennej soup
Objekt BeautifulSoup priradený premennej soup sa vytvorí s dvoma argumentmi. Prvým argumentom je HTML, ktoré sa má analyzovať, a druhý argument, reťazec "html.parser", hovorí objektu, ktorý parser sa má použiť v zákulisí. "html.parser" predstavuje zabudovaný parser HTML jazyka Python.
Použime obejkt BeautifulSoup
Uložte a spustite uvedený program. Po jeho spustení môžete v interaktívnom okne použiť premennú soup na rozbor obsahu html rôznymi spôsobmi.
Objekty BeautifulSoup majú napríklad metódu .get_text(), ktorú môžete použiť na extrahovanie celého textu z dokumentu a automatické odstránenie všetkých značiek HTML.
Do interaktívneho okna IDLE zadajte nasledujúci kód:

V tomto výstupe je veľa prázdnych riadkov. Sú to znaky nového riadku v texte dokumentu HTML. V prípade potreby ich môžete odstrániť pomocou metódy string .replace().
Často potrebujete z dokumentu HTML získať len určitý text. Použitie metódy Beautiful Soup najprv na extrakciu textu a potom pomocou metódy reťazca .find() je niekedy jednoduchšie ako práca s regulárnymi výrazmi.
Niekedy sú však samotné značky HTML prvkami, ktoré poukazujú na údaje, ktoré chcete získať. Napríklad možno chcete získať adresy URL všetkých obrázkov na stránke. Tieto odkazy sa nachádzajú v atribúte src značiek HTML.
V tomto prípade môžete použiť funkciu find_all() na vrátenie zoznamu všetkých inštancií tejto konkrétnej značky:





Modul urllib, s ktorým ste doteraz pracovali v tejto príručke, je vhodný na vyžiadanie obsahu webovej stránky. Niekedy však potrebujete interakciu s webovou stránkou, aby ste získali potrebný obsah. Môžete napríklad potrebovať odoslať formulár alebo kliknúť na tlačidlo, aby sa zobrazil skrytý obsah.
Štandardná knižnica jazyka Python neposkytuje vstavané prostriedky na interaktívnu prácu s webovými stránkami, ale v PyPI je k dispozícii mnoho balíkov tretích strán. Medzi nimi je MechanicalSoup populárny a pomerne jednoducho použiteľný balík.
MechanicalSoup v podstate inštaluje tzv. headless browser, čo je webový prehliadač bez grafického používateľského rozhrania. Tento prehliadač sa ovláda programovo prostredníctvom programu v jazyku Python.
Nainšťalujte MechanicalSoup
MechanicalSoup môžete nainštalovať pomocou pip v termináli:
$ python3 -m pip install MechanicalSoup
Vytvorte Browser Object
Do interaktívneho okna IDLE zadajte nasledujúce príkazy:

Objekty prehliadača predstavujú webový prehliadač. Môžeme ich použiť na vyžiadanie stránky z internetu odovzdaním adresy URL ich metóde .get():

Odoslanie formulára pomocou MechanicalSoup
Otvorte stránku /login z predchádzajúceho príkladu v prehliadači a pozrite sa na ňu predtým, ako budete pokračovať. Skúste zadať náhodnú kombináciu používateľského mena a hesla. Ak uhádnete nesprávne, v spodnej časti stránky sa zobrazí správa "Nesprávne používateľské meno alebo heslo!".
Ak však zadáte správne prihlasovacie údaje (používateľské meno zeus a heslo ThunderDude), potom budete presmerovaní na stránku /profiles.
V ďalšom príklade uvidíte, ako pomocou programu MechanicalSoup vyplniť a odoslať tento formulár pomocou jazyka Python!
Dôležitou časťou kódu HTML je prihlasovací formulár - to znamená všetko, čo sa nachádza vo vnútri
tagy. Ten na tejto stránke má atribút name nastavený na login. Tento formulár obsahuje dva prvky, jeden s názvom user a druhý s názvom pwd. Tretím prvkom je tlačidlo Odoslať.
Teraz, keď poznáte základnú štruktúru prihlasovacieho formulára, ako aj prihlasovacie údaje potrebné na prihlásenie, pozrime sa na program. ktorý vyplní formulár a odošle ho.
V novom okne editora zadajte nasledujúci program:
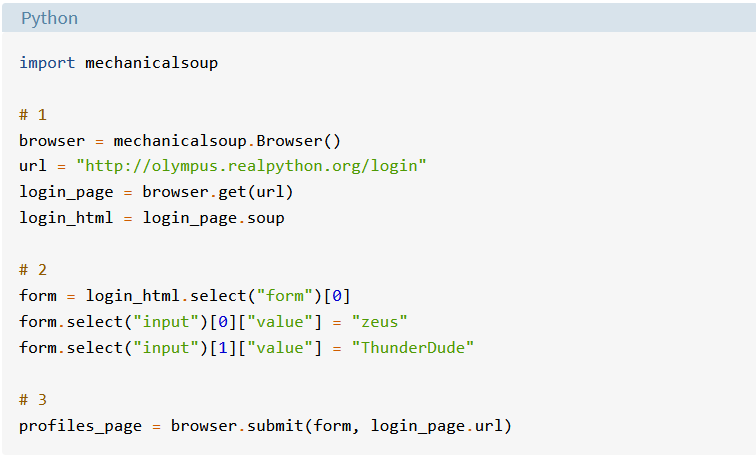
Uložte súbor a stlačte kláves F5, aby ste ho spustili. Úspešné prihlásenie môžete potvrdiť zadaním nasledujúceho textu do interaktívneho okna:

Použitie BeautifulSoup v projekte
created with
Website Builder Software .